Our mission here is to educate everyone about zero-knowledge proofs and show that you might be using them sooner than you think. We'll walk through some examples and explain how Revolve Polling makes use of this technology.
Let's start with a definition:
A zero-knowledge proof is a statement that something is true without having to reveal any information beyond the validity of this statement.
It typically involves one party generating a proof and presenting it to another party who verifies it. For our discussion today, we’re looking at how zero-knowledge proofs provide privacy technology.
Of course, it’ll be much more helpful to explain with a few examples. We'll start with a basic math formula to outline some concepts then move on to a real world privacy-preserving protocol that is used in Revolve Polling.
A Basic Math Formula
We need to cover algorithms briefly before we jump in. An algorithm is a series of steps that takes some input values, performs some operations and provides a result, the output.
This math formula can be considered an algorithm:
$$ z = x^2 + y $$
In our case here, x and y are the input values and z is the output. The steps are squaring x then adding y.
Now we’re ready to look at a zero-knowledge proof example.
So to start off, a proof system has to be set up. The proof system publicly establishes the inputs, outputs and algorithm steps. This allows anyone to generate one of these proofs and anyone else to verify it. As well, inputs can be marked as private during the set up process, keeping them hidden in the final proof data bundle.
Let's say Bill wants to prove to Sam that he knows some values, x and y, which were used in calculating the result z but he wants to keep x and y private.
Bill can make use of the proof system to generate a zero-knowledge proof, p, that he knows these two values and that they were used as inputs in the math formula to produce the result z.
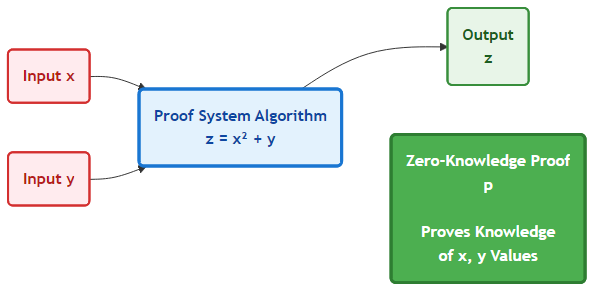
Bill can now present the proof p along with the output value z to Sam, who is able to make use of the proof system to verify that p is in fact a valid proof. Sam can confidently say that Bill must know some values, x and y, that were used to provide result z.
The magic here is that Bill did not need to share x and y, just a proof that he knows them. This proof provides zero-knowledge about the inputs and the work that was done in executing this algorithm.
You can now see the power of zero-knowledge proofs. The ability to keep secrets and provide verifiable proof that assures external parties about your knowledge of those secrets. The next example will unfold the details of a more advanced protocol, where we anonymously signal our identity.
Also, you might be wondering how this is different from other forms of cryptography like encryption. If Bill and Sam were using encryption, all information would be shared between them but hidden from potential onlookers or middlemen. Zero-knowledge proofs on the other hand keep information private for a single entity and allow proving knowledge of that information to anyone.
A Private Identity Protocol
Now that we’ve covered a basic example, you might have a slightly better idea of what zero-knowledge proofs are and how they work. Next we’ll take a look at the technology that powers Revolve Polling, specifically the project that provides anonymity for users when they submit survey responses.
This project is called Semaphore. It was built and is maintained by the Ethereum Foundation. I’ll provide the ‘What Is Semaphore?’ overview in their own words:
Semaphore is a zero-knowledge protocol that allows you to cast a message (for example, a vote or endorsement) as a provable group member without revealing your identity. Additionally, it provides a simple mechanism to prevent double-signaling.
For anyone interested in learning more about zero-knowledge technology, Semaphore provides a fantastic foundation for understanding the concepts and code. It is highly recommended to look at their work. We’ll take a high level look at the project here and discuss how it provides privacy for users of Revolve Polling.
Let’s paint a picture of how it is used first:
A collection of verified residents of British Columbia are stored in a group together. A survey is pushed to each user's device and they select their responses. Before making a submission, each user generates a zero-knowledge proof that they are a member of this group without revealing which member they are. They are now able to submit their survey response as a verified, anonymous resident of BC. This ensures accuracy in the overall results and maintains dignity for our users who are able to privately share their views. A win win for everyone.
Now we’ll look at the core concepts of Semaphore: Identity, Groups and Proofs. As well, we’ll explain the mechanism which prevents double-signaling and outline its critical role for research technology. There will be some computer science concepts and cryptography used but everything will be appropriately explained.
Identity
- A Semaphore Identity is a public key pair (private key and public key) as well as what’s called an Identity Commitment, which is a hash of the public key.
- If you are unfamiliar with public key cryptography or hashing, don't sweat it, we'll cover the important stuff:
- Public key cryptography: All that is important to point out here is that a Semaphore Identity has a private component and a public component. The private component is very securely stored on a device, never to be shown to the wider world. The public component is openly shared as a personal identifier.
- Hashing: A one way function which takes an input of any size and produces a consistent, fixed sized output. It's great for combining data and getting an irreversible digital fingerprint of sorts.
- In Revolve Polling, our users generate a Semaphore Identity in the mobile app. The private key is securely stored and their Identity Commitment is shared with us after successfully passing ID verification.
Groups
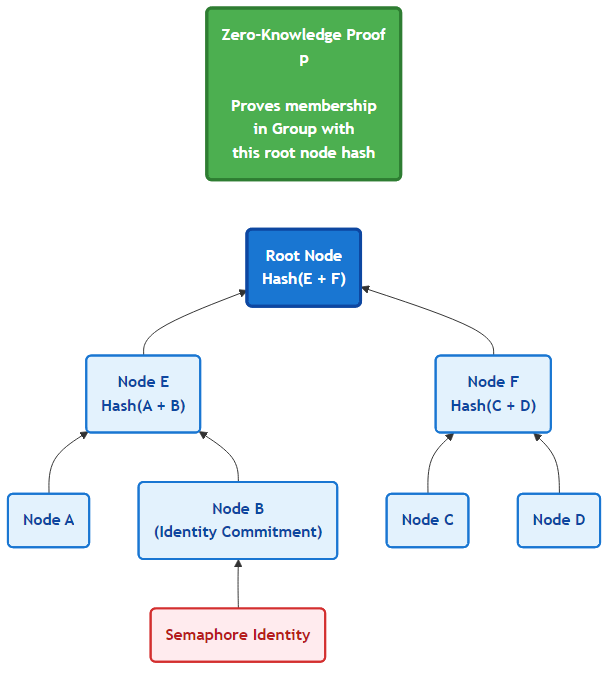
- A Semaphore Group is a collection of Identity Commitments. So for example in Revolve Polling, we create a British Columbia Group and all verified residents of BC would have their Identity Commitment added to that Group.
- In a more technical sense, Semaphore Groups provide a Merkle tree data structure. We’ll cover the essential details below.
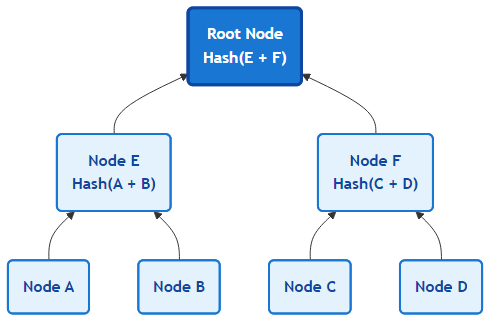
- Each of the lower nodes in the diagram are leaf nodes and each leaf node contains an Identity Commitment. You can see how they are combined together and then hashed to give the intermediate node above it.
- This process continues until finally the very important root node is computed. The root node serves as a fingerprint of sorts for the entire Group and will be updated every time a leaf node is updated.
With the concepts and data structures we’ve looked at so far, we’re now ready to bring everything together and explain how zero-knowledge proofs work in Semaphore and you’ll begin to see the actual wiring that provides anonymity for users of Revolve Polling.
Proofs
- So let’s recall our discussion about proof systems from the original example. They were defined as a publicly established system that describes the inputs, outputs and algorithm steps. As well, inputs are marked as private during the set up of the proof system.
- The Semaphore algorithm can be summarized in a few steps:
- Input Semaphore Identity
- Generate Identity Commitment from Semaphore Identity
- Hash the nodes from the leaf node which contains that Identity Commitment up until the root node
- Finally the root node hash is returned as the output
- This proof system requires inputting a Semaphore Identity (which is marked as private) and outputs a root node hash from the tree. The algorithm proves that a user is a member in a Group that has a certain root node hash.
Nullifier
- If you remember from the Semaphore definition, they mentioned that it “provides a simple mechanism to prevent double-signaling”.
- We’re going to cover this quickly as it showcases how Revolve Polling can ensure accurate results and survey resubmission flexibility at the same time.
- We didn’t tell the full story in the Proofs section. There is actually another input and another output in this proof system:
- This additional input is called a scope. It refers to what you are generating the proof for. In Revolve Polling, this is a unique number assigned to each survey.
- The additional output is called a nullifier. It is a hash of a user's Semaphore Identity and this scope value.
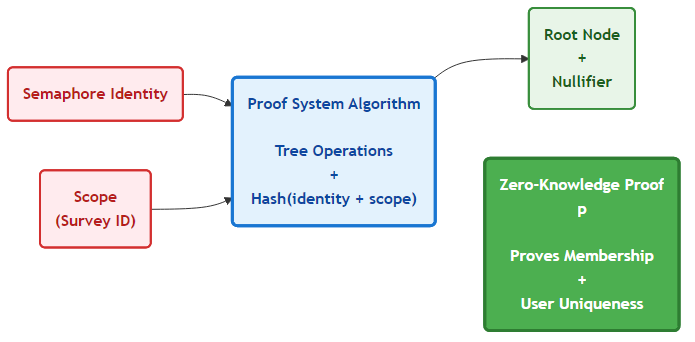
- What we really get with the nullifier is a consistent, non-identifying output value that maps a user to a survey. This way if a user resubmits a survey response, we can replace their previous response. This maintains a unique response set and the user's anonymity.
So there you have it, that’s how a real zero-knowledge proof protocol works. What might sound like magic or even impossible when you first hear it, is hopefully demystified a bit.
We’re excited to use Semaphore in Revolve Polling and take a step into barely explored territory with research technology. The benefits are clear and it’s our genuine hope that Canadians will be excited to take part in contributing to the evolving consensus on all kinds of issues.
If you have any further questions, please feel free to reach out!